-
[딥러닝의 이해] 학습이란? + Loss FunctionStudies/Data Analytics&ML 2023. 9. 17. 17:47
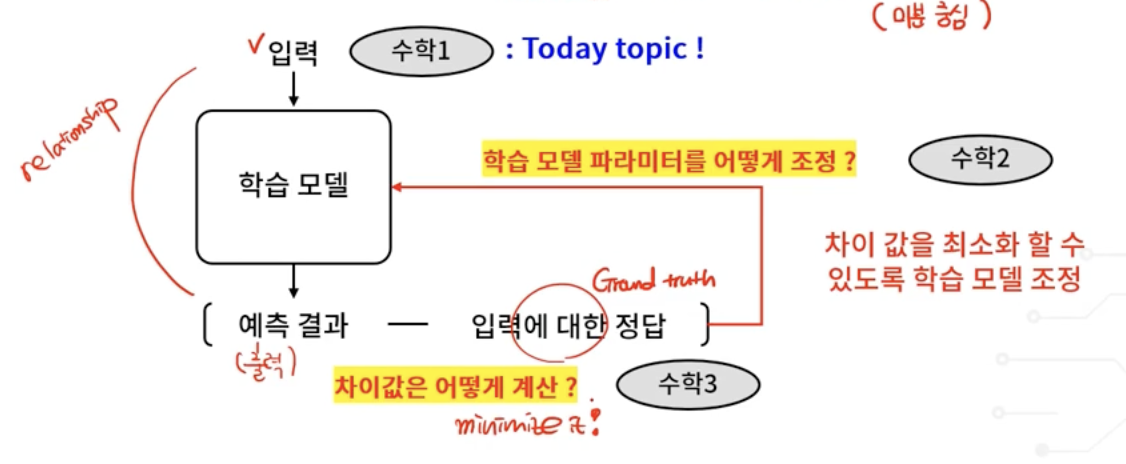
- 학습의 목적 : 정답과 예측 결과의 차이를 최소화
crieteria (기준)
input -> ( predicted result - ground truth(정답) ) minimize
idle case는 predicted result - ground truth(정답) = 0
-> 수학적 도구가 필요 (선형대수 , 확률론 , 최적화 이론(미분 중심))
predicted result - ground truth(정답)

딥러닝을 위한 수학적 배경
- 선형대수학 , 확률론 , 및 최적화 이론 (미분 중심)
- 데이터 가공부터 학습 및 테스트까지 모든 과정에서 수학 이론 필요
딥러닝을 위한 데이터 구조
- Tensor (텐서) : 데이터 덩어리
- Scalar / Vector / Matrix : 모두 Tensor의 다른 형태

Tensor
- Matrix의 예 - gray scale 이미지
- Tensor - 데이터 덩어리

데이터 정규화(Normalization)
값이 큰 모델에 대하여 overfitting됨
-> 입력 데이터 간 값의 분포 범위를 동일하게 설정
- min-max normalization

zero-centered = 평균이 0이다 = 모든 data에서 평균을 빼주면 된다

normalization
How to estimate the accuracy of prediction?
- Loss(손실) : 정답(Ground truth)과 모델이 예측한 결과의 차이
- Such difference needs to be minimized
- Loss Functions
- Convergence(수렴성)
- Loss가 진동하지 않고 수렴해야함
- Minimization
- Convergence(수렴성)
- Types of loss functions
- Max-based loss computation
- Support Vector Machine
- Probability-based loss computation
- softmax(cross entropy)
- Max-based loss computation

- inner product
- 평행할 때 (allign) 최대
Gradient
- Loss를 Weight에 대하여 미분한다

'Studies > Data Analytics&ML' 카테고리의 다른 글
[머신러닝] 회귀(Regression) (0) 2023.01.23 데이터 살펴보기 (판다스/데이터프레임) (0) 2022.09.25